13 Temmuz 2016 Çarşamba
19 Mart 2016 Cumartesi
6 Ocak 2016 Çarşamba
Western blots versus parallel reaction monitoring (PRM)!!
This week I visited a lab that has been doing some great validation work with parallel reaction monitoring (PRM). While preparing their work for publication, one of their collaborators began insisting that they "validate" their findings with western blots. I don't know about them, but I felt like I'd been playing Jumanji....

It is 2016 (despite what you've been writing at the top of every page!)!!! Holy cow. I know I'm typing to my imaginary choir here, but I really want to get this out of my system. Surprisingly, though, no one has really done a head-to-head comparison of PRM versus Western Blots that I can find and I'd like this rant to pop up when I type the two terms into Google. There is, however, a ton of material to pull from to support my rant.
I hereby present: Western blots versus Parallel Reaction monitoring!

In the red corner we have Western Blots. There is a great wikipedia article on this methodology here.
Basically, though, you do this:
1) You run an SDS-PAGE gel
2) You transfer the proteins via more electricity to a membrane (sucks 'em right out and they stick to the membrane
3) You soak the entire membrane in a solution containing a commercial antibody raised against a peptide within your protein of interest. (They do this by injecting a peptide from your protein of interest into a rodent, or camel, or horse. Typically a rodent, though. For this example, lets say its a bunny rabbit.
4) You wash away bunny rabbit antibodies that don't stick to your membrane in a super tight way
5) Then you add a solution to your membrane that has an antibody with a detection region and a region that binds to any bunny rabbit antibodies
6) Then you activate your detection. That detection region might light up (fluorescence) or it typically causes a chemical reaction that makes a dark spot where stuff matches.
Amazing technique when it was developed in the 70s. It is, of course, still super powerful today, but it has weaknesses that have been addressed many times. First of all, it relies on the efficacy and specificity of two commercial antibodies. I know this is ancient history, but in 2008 Lisa Berglund et al., did a high-throughput analysis of commercial antibodies and found that a large number of them did not work at all. In fact, the average success rate of the 1,410 antibodies they tested was an awe-inspring 49%. I'm sure those numbers have went way way up. However, according to this 2013 article in Nature Methods, the field of antibody production contains over 350 separate producers. Despite this level of competition, the paper appears to recommend returning antibodies as a step in normal lab practices. Hey, no one is perfect, but I'm just throwing these articles out there.
Let us assume that the antibodies you've ordered have been used by tons of groups and that they work just fine. Chances are that you can find a protocol that will give you a good method for step 4 above. If you don't wash away non-specific binding you will just get a blot full of signal. If you use a wash that is too stringent, you get nothing at all. Hopefully someone has done this work for you! If not, you're on your own. And then you have to wonder...is it the antibody? or is it me? Probably a good idea to run it a few more times. At 4-5 hours a pop with the newest technology and not one single glitch along the way, it might take a few days to optimize a new assay.
I found this nice picture on Google Images, I'd like to share (original source unknown):

Parallel Reaction monitoring!

The figures for PRM are taken from this great recent (open access!) review by Navin Rauniyar.
Here are the steps
1) You start with a pretty good estimate of the mass of some peptides from your protein of interest and you use that for the quadrupole (or ion trap on LTQ-Orbitrap instruments. Yup! You can totally do this on hybrids, but it works better on quadrupole-Orbitraps) isolation. You can easily refine your data acquisition by retention time or by focusing the isolation to reduce background and increase specificity
2) You fragment the ions you select
3) You match the high resolution accurate mass fragment ions to the theoretical (or your previously experimentally observed fragments) within 1 or 2 ppm (really, no reason to ever go above 3 ppm.)
4) Post processing allows you to drop fragment ions that might not be as specific as you'd like and you can use the intensity of your fragment ions cumulatively to score your signal. Once you have your favorite fragment ions your rerun your PRM method for the samples you'd like to compare.
HEAD to HEAD time!
Category 1: Reproducibility
According to references in this paper from Dan Liebler and Lisa Zimmerman, the CV of a western blotting measurement ranges from 20-40%. In this paper from S. Gallien et al., all PRM measurements in unfractionated human body fluids were found with CVs less than 20%. 5% is common.
Winner? PRM!
Category 2: Time
There are a bunch of new technologies for western blots including fast transfers and fast blotting and direct signal measurements. If we assume you're using something like that and it takes you 2 hours to normalize, load and run a gel (you are faster than me). You can get this down to 4-5 hours. Now, you can use multiple lanes. But this also involves man hours, where you have to be moving things, transferring things, blah blah blah.
Winner? In pure time with newest technology? Western blots, maybe. In time (measurements per work day? Definitely PRM.
Category 3: Sensitivity
A chart on this page says you can get sensitivity down to the femto/pico range (in grams.) Since proteins have masses in the kDa range and we measure LC-MS sensitivity on new instruments in the femto and atto-mol range, unless I'm not awake yet, this seems pretty clear.
Winner? PRM by a bunch of zeroes!
Category 4: Specificity
Antibodies are awesomely specific. But they are often raised against one peptide. PRMs of multiple peptides can easily be set up. And you can choose targets AND fragment ions with the level of specificity that you need. Commercial antibody providers will obviously take this stuff into account, but this control is often out of your hands. And its one peptide. You can see in the blot pictures above that you may often get multiple targets. You can narrow it down by SDS-PAGE determined average mass. OR you can choose multiple peptides that are unique in evolution and you can use the retention time of those peptides and fragments that are unique in evolution, within a few electrons in mass?? This one seems pretty darned clear to me..
Winner? PRM!!!!
Category 5: Cost
Starting from scratch? A full setup to do Western blots is gonna be a lot cheaper than an Orbitrap. But, you know, if you are reading this and you don't have a mass spec you just might have too much time on your hands. If you already have a HRAM LC-MS setup, you don't need anything additional for relative quantification via PRM. For absolute quan you'd want some heavy peptide standards. If you have both the capabilities to do western blots and PRMs in your lab, the antibodies, gels and membranes are additional costs/experiment.
Winner? (If you already have a mass spec that can do PRMs?) PRM!
3 Ocak 2016 Pazar
No ID for your cross-linked peptides? Maybe you aren't looking for the right things.

Cross-linking reagents are such a great idea for studying lots of things. But they can be some cumbersome to work with that a lot of groups just ignore them altogether. Sven Giese et al., thought it would be worth it to take a deeper look at high resolution CID fragmentation nearly a thousand known cross-linked species to see if we just aren't looking for the correct fragment ion species with our typical techniques.
Turns out that might be exactly what is happening. Taking what they learned from the known peptide high resolution study, they were able to boost the identification rate of their unknowns by 9x over traditional search engines.
Worth noting that they did a lot of this with custom coding in Python, so these tools might not immediately be accessible to all of us, but I bet some smart coder could integrate this info into some user-friendlier tool!
1 Ocak 2016 Cuma
Cause no one ever asked for it! My favorite papers of 2015!

(Picture from PugsAndKisses.Com)
This is definitely my favorite post of the year. This is where I get to go back through this ridiculous hobby of mine and re-read my interpretations about the amazing work you guys are doing out there! (An added benefit is that I get to fix typos, errors and even delete some of the dumber things I've typed.)
There was SO MUCH great stuff published this year. I know I only read a tiny fraction, but I now have 17 tabs open that I'm trying to narrow down. I'm going to start with the 2 that really stand out in my mind
PROMIS-QUAN -- The most proteins ever ID'ed in a plasma sample isn't some analysis where someone did 2D fractionation and 288 hours of runs? No, its one single LC-MS run? When friends outside my field ask me how the technology is progressing, I tell them about this paper. I hope hope hope it is real. I feel equally impressed that this group came up with this and equally stupid for not thinking of it, because it is so simple and so so brilliant.
Intelligent acquisition of PRMs -- I really think PRMs are the future of accurate quantification. You get your ion and you know it really is your target because you have basically ever fragment of one species with accurate mass, typically within 1ppm or 2. Problem is they are kinda slow. So these crazies in Luxembourg go and write their own software so that they can intelligently acquire their targets based on the appearance of heavy labeled internal standards? This is a study that is so good, the PI makes this list even though he didn't respond when I asked him for a slide from his HUPO talk. Tie this in with a lot of mounting data that PRMs can be as sensitive or more than QQQ and you start to wonder what routine labs are gonna look like in the near future...
LC-MS can be both reproducible AND accurate -- The genomics/transcriptomics people get to eat our lunch sometimes due to the belief in general science that we aren't very reproducible. So a bunch of smart people get together and show that our biggest problem, as a field, may be that we don't have common sample prep techniques, cause if you prep samples the same way it doesn't seem to matter where your mass spec is or who runs it...

(within reason, of course)
... you can get the same data.
Speaking of sample prep:
How 'bout massively speeding up FASP reactions with mSTERN blotting, iFASP, or change gears entirely with the SMART digest kits? Which one should you use? I don't know! I'm just a blogger. How 'bout a bunch of you smart people get together and decide which one and lets shake off this whole "proteomics isn't reproducible" bologna and get all the money people are spending on those weird, shiny (and crazy expensive!) RNA boxes.
Oh yeah! On the topic of those RNA boxes, PROTEOGENOMICS!
Probably my favorite primary research paper on this topic this year (man, there were some great ones!) I can think of was this gem in Nature. We also saw several great reviews, but this one in Nature Methods was likely the most current and comprehensive one that I spent time on. Is Proteogenomics still really hard to do? Sure! Does it look worth it? Yeah, I still think it does, and it'll get easier at some point!
There were some proteomics papers that transcended our field this year as well. Probably the biggest one was the pancreatic cancer detection from urine that the good people at MSBioWorks were involved in. Another one I liked a lot was the Proteomics in Forensics out of the Kohlbacher group. Apparently you guys liked it as well, cause my blurb on it was probably my most read post of the year.

[Previously my opinions on another paper that were a bit negative occupied this spot. I chose to delete a few minutes after posting. Lets keep this positive! Insert Gusto instead!]
Now it gets a little random! Just things that occur to me this morning as really smart.

[Previously my opinions on another paper that were a bit negative occupied this spot. I chose to delete a few minutes after posting. Lets keep this positive! Insert Gusto instead!]
Now it gets a little random! Just things that occur to me this morning as really smart.
How 'bout going after non-stoichiometric peptides and PTMs? When I mention this to people it still seems a little controversial but biologically it makes an awful lot of sense. This year we also either saw a lot more glycoproteomics because that field is advancing on all fronts or I was just more aware of it. I think its the former, though. A great example was this paper out of Australia. It was another big year for phosphoproteomics, with new enrichment techniques, incredibly deep coverage studies, reproducibility analyses, applications of quantification and even new tools to analyze all that phospho data!
Another one that sticks out to me was Direct Infusion SIM (DISIM?). If you need to quantify something fast, turns out you can direct infuse the target and you can get some good relative quantification. Makes sense to me, and they have the data to show it works, so why not!?!
Okay, I've been working on this one for way too long. Ending notes: Holy cow, y'all did some awesome stuff in 2015! THANK YOU!!! I can't wait to see what you've got for us this year!!!!
29 Aralık 2015 Salı
CPTAC shows high reproducibility in Orbitrap quan between systems AND methodologies!

Once in a while I run into someone who heard from someone else that Orbitraps aren't good for quantification.

Our good friends at CPTAC decided to make the ultimate comparison. Over 1,000 (one-thousand!!!) LC-MS/MS runs. From different mass spectrometers. From different institutes. With different quantification technologies. On xenografts! (That's a human tumor grown on a mouse. You don't get much more variable).
They compared iTRAQ quan with XIC based label free quan (peak area integration) and spectral counting. What did they find? I'll just quote it.
"If laboratories deploy different methodologies to analyze the differences between the same two complex samples, then they will assuredly see differences in the gene or protein lists produced by the two technologies. The degree of conformity observed in this study, however, was encouraging. When label-free data were analyzed by spectral counting rather than precursor intensity, the differences yielded a high degree of overlap. When iTRAQ rather than label-free methods are deployed, the differential genes were again quite similar. These overlaps suggest a degree of maturity in proteomic methods that has grown through years of development along multiple tracks.
At base, biologists need to know that differential proteomics technologies can produce meaningful results. Our assessment showed that biological pathway and network analysis is highly consistent across instruments."
Right?!? Ben's interpretation: We're still getting a subset of the data in something as complex as a human tumor. We can bias this subset by using completely different methodologies, but even on the most complex human samples and experiments, we're at a point where we are HIGHLY reproducible. And this is the global/fractionated stuff....
28 Aralık 2015 Pazartesi
Protein carbamylation is a hallmark of aging - and how to detect it

A recent paper in PNAS makes the statement in the title "Protein Carbamylation is a Hallmark of Aging. You can find it here.
They find that you can almost assess the age of a mammal by looking at the degree of carbamylation in the proteins of that mammal. I'm not 100% awake yet, so it took me a minute or two to remember what carbamylation was and why it puts up a little alarm in my head. Then I found the image above. Most of the time when I think about carbamylation, its cause its a sample prep issue.
Here is a paper that discusses this modification. When I run Preview on a sample and it pulls up carbamylation as a modification to consider I've always assumed it is from a protein prep in which either excessive Urea was used, or Urea was used and the prep was performed at too high of a temperature. Turns out, it might be detecting old samples as well? Interesting thought, right?
Detection of this modification is very straight-forward in any search engine. In PD you just need to activate the modification in the Administration --> Maintain chemical modifications tab.

With this valuable new information, I expect y'all to get on reversing this aging stuff 'cause the more I experience it the more I realize I'm NOT a fan of it.
27 Aralık 2015 Pazar
Pinnacle -- the best translational software I've ever seen.

I've been wanting to talk about this one for months!!! Unfortunately, I do have a day job and there are rules I have to follow to keep that day job, so I held my tongue until I found out I was finally allowed to talk about it this week.
At HUPO I got to see Pinnacle. Pinnacle is software specifically meant for all you translational people out there. I know, there is a ton of software out there, but I'm going to argue that you ought to demo this one if:
1) You have so many clinical samples (especially high resolution ones) that you can't process them in anything like a reasonable amount of time
2) You are doing label free quantification
3) You are doing data-independent analysis (DIA, pSMART, WiSIMDIA)
4) You just want to use a piece of software that is graphically pretty.
This software is fast. Sick fast. It-shouldn't-possibly-be-this-fast FAST. Put in HUNDREDS of Q Exactive Raw files -- targeted, untargeted, DIA, whatever -- and watch it pull the data out in minutes.
Wonder what the data quality is like? Just look at color and shape of the icons on the left (click on the pic above to zoom in) and get a feel for the quality OR look to the right of the peptide sequence where you ACTUALLY SEE THE INTEGRATED PEAKS. Sorry to shout, but how cool is that? "Wow, that is crazy upregulated! Should I investigate it? Nope, that is obviously just a poor integration. Better readjust that integration right now". In real time. Without changing the settings and reprocessing the data. Just fixing that peak. Click, click, done.
Pinnacle has a bunch of other functions. Its a thorough software package and you purchase the modules that you need for your work. You can also download a free trial version here that lets you process one dataset and see what I'm talking about.
26 Aralık 2015 Cumartesi
Interesting, though somewhat morbid, article on elite scientists and progress

I'm not entirely sure what to think of this. Partially because I'm having a little bit of trouble wrapping my head around it. Maybe part of the difficulty is that the article is from the National Bureau of Economic Research. Which, Wikipedia tells me, is a real thing.
Anywho...you can read the article I found on Vox here.
And the abstract for the original article is here (there is a $5 charge to download the complete article)
25 Aralık 2015 Cuma
Christmas Magic -- Multiply charged proteins ionized with no energy!

This is really interesting. What if you could just mix up your proteins, including the big ones with your matrix compound(s) and then magically get multiply charged species into your mass spectrometer? No energy. They just grab some protons and go flying into the air? Well, it sounds like you could save a lot of energy on lasers....AND....maybe you could finally give up on that weird old TOF in the corner that can go to 100kDa (you know...the one that is 8 foot tall and has accuracy within 1kDa...or 2...)
Well, that appears to be exactly what happens. What?!!? I know!
Check out this paper from Sarah Trimpin for more details. Hey, if nothing else, it has one of the single most amusing abstracts I've ever read.
And its got this great chart!

24 Aralık 2015 Perşembe
CaspDB - A database of caspase cleavage products!
Another tool to help find identifications for unmatched MS/MS spectra! Caspases are proteins that hang around just to destroy other proteins. They are a critical component of apoptosis and normal cell maintenance, and if you believe the recent in silico protein cycle predictions -- they are active constantly. If my mix of proteins I just harvested is full of incomplete, complete, modified AND degraded proteins, then all these unmatched spectra start to make sense.
Caspases have specific substrates for degradation and a bunch of them have been worked out. CaspDB is a new online tool to help you work with this this information. It is described in this new Open Access paper from Sonu Kumar et al.,.
While the paper is totally neat and all, you can go directly to check out this online tool here. You'll quickly find out that this tool requires a good bit of pre-existing information before it is useful. Once you've got some data, you can use it to run through your protein of interest and different caspases to see if you've got stuff that makes sense. The paper goes forward to show how awesome these prediction tools are by going ahead and proving that a ton of their software predictions are totally true.
This is obviously a very powerful and interesting tool and this will generate some great data from the validation end. But first you need to get some observations....

...(how did we ever get anything done before this...????...)
Check out this thing!!! Its called Pripper and, wait, we'll need this...

...to go WayBack to 2010....to this paper from Mirva Piippo et al., that describes Pripper. Pripper is a Java tool that will take any FASTA database you give it and will perform in silico caspase cleavages on that database and give you a new FASTA that has all the predicted caspase cleavage products.
If you're thinking "How can I trust a tool that is 5 whole years old?" Never fear, it has been updated multiple times (the version I just unzipped is time stamped from 2013). Oh. If you download Pripper here you might want to right click on the zip file, go to properties, click "unblock" then "apply" and THEN unzip it. Windows Defender on my PC blocked it as a threat.
Now you have a tool that will make you a predicted caspase cleavage FASTA that you can run against your samples. If it comes up with something really cool then you can go to the CaspDB and search those observations against their more advanced prediction models (and validated data!)
23 Aralık 2015 Çarşamba
What is a PFAM? And how do they deal with all this data?
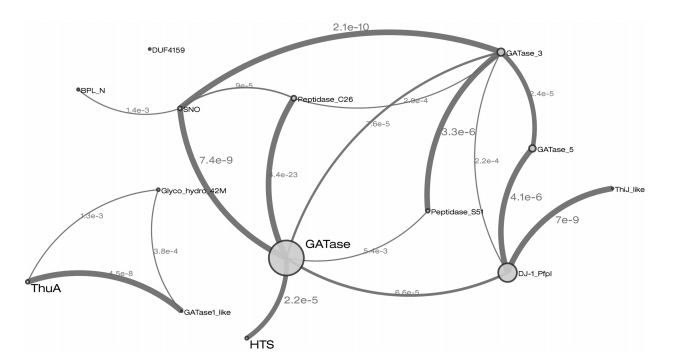
Personally, I think the biologists and biochemists need to hurry up and annotate the function of every protein from every organism under every biological condition. Until they stop slacking and get that stuff done, we need to use some shortcuts to extract biological data from our peptide spectral matches. Fortunately, smart people have been working on this gap for us.
Gene Ontology (GO) is tricky stuff. If we don't exactly know what a gene does can we infer from its similarity to genes we better understand what the heck it does?
More tricky, and way more biologically relevant? Protein Ontology (PO?)! One way of getting this data is via PFAM (which you can access here). I'll be honest. I didn't really know what this is was for a long time. I just knew that it was an option in the Annotation node in Proteome Discoverer. Cool, I have new column that says that all this stuff that is upregulated shares a PFAM ID (actually, I made that part up. Its never that easy, is it?)
Turns out that the people making PFAM are working really hard making this data:
1) More accurate
2) More relevant
3) More current
As you can imagine, all of this is hard, but...

Can you imagine what the 3rd one is like these days?
The amount of sequencing information in databases is increasing EXPONENTIALLY and the current tools for creating PFAM information increases at a linear rate. It doesn't take a stolen GoogleImage to show that this is a problem, but...I'm nervously waiting for an important phone call...so...

So, what do we do about it? Well, Robert Finn et al., say in this new OpenAccess paper, we fix the algorithms to deal with this glut of data. So they did.
When I clicked on this link in Twitter this morning, I honestly expected a dense paper that I probably would hardly be able to read and would likely not understand at all. I was pleasantly surprised to find that this team can seriously write and that I not only learned a lot about how PFAM works, but I also (think) I got a good understanding of their challenges and how their new algorithms power through in dealing with them. Solid and interesting paper that makes me want to add this column to all of my processed data from now on!
22 Aralık 2015 Salı
Updated guide to connecting your NanoLC-MS!

Got a Thermo nanoLC? Wanna connect it to a Thermo mass spec? Want every frickin' part number and easy to follow diagrams?
TAAADAAA!!! This link will lead you to a new and updated version of the nanoLC connection guide. It is at PlanetOrbitrap so you might need to log in and then re-click the link to get directly in.
21 Aralık 2015 Pazartesi
PTMs in centromeres!

I had to dig deep in my brain and then finally just look at Google Images to remember what a centromere is and why its important. Hopefully the nice sketch I found above clarifies it for you as well. Cause its the protein that holds chromosomes together. Its gonna be deeply involved in cell/chromosome division, sexual reproduction and probably all sorts of other things.
In this new paper from Aaron Bailey et al., in press (and currently open access) at MCP this group looked at the post-translational modifications that can show up on these important proteins.
They started with a HeLa cell line that had a stable affinity tag at some centromere and then immunoprecipitated to get at their proteins of interest. Chemicals were used to arrest the cells in certain stages of mitosis or something. Multiple enzymes, including LysC and AspN were used to get big chunks of the cleaned up protein for effective PTM identification and localization.
What did they find?

20 Aralık 2015 Pazar
BetterExplained -- a great site for math concepts

I seem to have forgotten all the little that I ever knew about Math. This site, BetterExplained, uses clever examples to either teach or remind you of what a match concept is.
16 Aralık 2015 Çarşamba
Open Genomics Engine

Sorry, this is something I just stumbled on that I didn't want to forget about! I lost the password to my EverNote account...but it does look super cool, right? If you're into that weird DRNA sequencing stuff, that is...
14 Aralık 2015 Pazartesi
Use protein solubility to get around protein abundance issues in biofluids?

For biofluids, one of the biggest problems is the high abundance junk. "Junk" probably isn't the right word since evolution probably wouldn't have erred toward filling our fluids with albumin if it wasn't important, but...you know what I mean....
In an interesting take to this problem, Bollineni et al., tried a protein solubility approach. Rather than specifically depleting the most abundant proteins using an immuno-affinity approach, they used different concentrations of ammonium sulfate to precipitate or solubilize different populations of plasma proteins. This gave them a less directly biased way of fractionating out the high abundance things.
To my friends out there who are in the "do not deplete!" camp, sure, you're probably going to run into the same problems, like the fraction that has albumin will pull down tons of interesting things with it. But for people who will accept this loss in order to see the stuff that isn't at 1e9 copies per uL this might be an simple approach to see something different than what your Top4,10, or 14 depletion column is giving you.
13 Aralık 2015 Pazar
proBAMsuite! Great new proteogenomics tools!

Man, I love a software package with a catchy title. And I love a free software package that has a ton of promise! proBAMsuite has all of these things!
Is a set of R tools that are meant to help you integrate the data from your next gen sequencing files with your LC-MS/MS spectra. This is an overview of the steps involved.

Of course, the process isn't trivial. The RNAseq data needs to be lined up and QC'ed and so do the MS/MS spectra and the PSMs and the Peptide matches. When we're looking at millions of measurements the number of false discoveries has to go up, just mathematically, nevermind the fact that not every MS/MS spectra or next gen read is as good as the others.
In order to control the false discoveries, the capabilities are in place to control the FDR at the PSM and peptide level. Even cooler, maybe, is this idea: The decoy matches are kept and allowed to be mapped against the total genomics data, so you can get a good idea of the FDR at the complete, reassembled level! Total system FDR.
Why would we go to all this trouble?
1) How bout more data about your protein than you'd maybe even want? Check out the suite's sweet output!

And, of course, more explanations for what those weird MS/MS spectra are!
Open access pre-release of paper here!
12 Aralık 2015 Cumartesi
The second version of the OpenMS LFQ nodes are available! Now for PD 2.1!

The label free quan nodes from OpenMS I keep going on about? Version 2 is now available! More stable, faster, and works in Proteome Discoverer 2.1.
You can get them here. Once this PC stops looking like this:

I'll install 'em and give 'em a good hard run!
Keep this good code coming, people!
10 Aralık 2015 Perşembe
Find unidentifed differentially regulated reporter biomarkers in reporter ion datasets!

I feel kind of smart for this one, though I'm afraid I'm getting to the point where I really really should get an indoor hobby of some kind since this is most of what I did last weekend. What do you guys do when its too cold to rock climb but you can't snowboard yet?
Anyway. I have access to an amazingly cool set of TMT/iTRAQ samples. I have access because there is a distinct and observable phenotype. Not a little one, either. The hundreds of samples in group 1 and group 2 are extremely different. Proteomics, so far, has shown just about nothing different between the two. Weird, right? For years we've been suspecting a novel mutational system or PTM that we've just never seen before, but we've not been able to find a way to hunt it down.
So, here was the thought that killed this last weekend: What if I completely ignored the IDs? What if I only looked at the spectra that showed a significant difference at the reporter ion level? And then I tried to figure out what they were later?
In PD 2.1 + Quan you can do this. There is a tab in your report that is your "Quan spectra".
You can actually go to that and look at every MS/MS spectra. You can see the RAW reporter values and you can even see your quantification spectra zoomed in.
So, you can actually go through and see all the stuff that is different. See the reporter ions above? This is exactly the trend I should be seeing in this sample set based on the phenotype. Exactly. And this MS/MS spectra is the most differentially regulated observation in this entire sample set of 1M or so MS/MS spectra. And this PSM shows up just like this three times in different, overlapping fractions. I think the precursor intensity for this is 1e6-5e6. More importantly, since in PD 2.1 we can plot our reporter ion intensities by their SIGNAL TO NOISE (yay!!!!!!), the S/N of these reporter ions are >500!!!
In sum, this is the perfect biomarker for this experiment and maybe the thing we've been trying to find in one form or another for 5 years (Holy cow, I don't think I'm exaggerating. Its 2015?!?!). Not to get my hopes up to high or anything....
Where it gets difficult, however, is linking that back to the full fragmentation spectra.
For example, check this out, and I'd LOVE it if you guys had advice. I'm putting in a feature request and will be bugging the great people at PD.Support but I'll take any ideas I can get.

Anything from the Protein/Peptide/PSM and MS/MS spectrum can be checked and exported to .DTA, mgf, or whatever. Then I can do big DeltaM searches in Byonic or DeNovo GUI it or PEAKS it.
But I've got to go through one at a time and find the MS/MS spectrum info to export. Kinda looks like next weekends gonna be a wash if I can't find a shortcut (cause I have about 200 interesting things to look at now that I have NO idea what the fudge they are!)
I suspect I'm looking at a PTM but I don't have anything to match any of our normal suspects. Or...I'm looking at unique class-switch sequences in the variable regions of antibodies! Either way, there are biomarkers in this dataset that traditional peptide searching can not identify and the dataset is just too big for Byonic WildCard, but here I've vastly reduced (computationally, at least...) the complexity of this problem! Will I find my biomarkers this way? Who knows, but on some of these hard datasets we need every lead we can get, right?
Again, if you have any advice or thoughts on how I might simplify this, I'd love to hear it!!!
Kaydol:
Kayıtlar (Atom)
Popular Posts
-
 A recent paper in PNAS makes the statement in the title "Protein Carbamylation is a Hallmark of Aging. You can find it here . They find...
A recent paper in PNAS makes the statement in the title "Protein Carbamylation is a Hallmark of Aging. You can find it here . They find...




